A popular job interview question is: at what point should QA get involved in the SDLC – Software Development Life Cycle? The answer is more or less: as early as possible. However, with tightening deadlines and testing usually getting squeezed out, getting involved at any point after code has been written is no longer soon enough.
Traditional TCOEs – Testing Centre of Excellence – encouraged segregation of testers and developers, required detailed documentation of every possible use case. This documentation, when turned into test cases, take an enormous amount of time to execute, and has no consideration for which parts of the application have actually been modified.
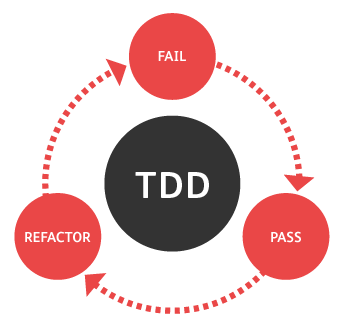
Test-driven development
TDD – Test-Driven Development – grew from the test-first ideas of Extreme Programming. At its most basic level, it says that the developer should work on any task in the following order:
1. Fail: Write an automated test that defines a piece of improvement or new functionality. Check that the test initially fails.
2. Pass: Write the minimum amount of code required to make the test pass.
3. Refactor: change the new code to acceptable standards. All existing tests (regressions) still have to pass.
The technique encourages simple design (if it is too hard to test, it is probably too complicated), and inspires confidence (the green light at the end of a build does wonders for morale).
The concept can be easily applied to improvements of legacy code, which often lack sufficient unit tests.
Following the TDD method often results in much higher test coverage, which also increases confidence and, usually, quality of the resulting code.
And while it is true that more code has to be written to account for the tests, developers often report that much less time is spent debugging code, which itself is a complicated and time consuming activity.
You are trying to produce faster delivery of the final product, not shorten development or testing times.
This technique also prevents testing from being squeezed out at the end of the project.
However, it is important to get management buy-in, especially in the case where management believes that tests are code that you cannot sell and therefore a waste of time. Management needs to realize that you are trying to produce faster delivery of the final product, not shorten development or testing times.
Another goal is lower defect count, which has hidden benefits such as increased customer confidence.
One interesting feature of this approach, is that a defect is not considered a bug in the code – it is considered a missing test!
However, it is important to keep in mind that TDD is meant for writing unit tests, which by itself is not sufficient testing. These tests are usually written by the developer who is also writing the code being tested.
It is very likely that both the code and the tests will share the same assumptions, which could be misinterpretation of specification or just plain wrong. Also, these tests can suffer from “checking is not testing”, which we discussed in the Why Test? article.
Additional testing at a higher level is required. This technique can be expanded to ATDD – Acceptance Test-Driven Development – also called: Specification By Example.
Specification By Example
Specification by example, or ATDD, considers test automation (what we have been mostly concentrating on so far) secondary. It is first a communication tool between the customer, developer, and tester to ensure that the requirements are well-defined.
A very important part of Specification By Example is the idea of a “single source of truth.” There are two aspects to this.
In larger corporations this can create definite challenges, which can be compounded by Agile methodologies that actually encourage very frequent changes and modifications.
By bringing these groups together, and getting them to collaborate on one set of documents – a single source of truth – eliminates the need for this synchronization, and forces better understanding of the problem and the design between these groups.
It is very difficult to describe the behaviour in general terms; it is much easier to come up with specific examples.
A second problem with traditional design specifications is that they usually try to describe the behaviour of the application in general terms, with very few (if any) examples. However, for particularly complex systems, it is very difficult to describe the behaviour in general terms; it is much easier to come up with specific examples.
Any missing gaps in the specification found during development, deployment, testing – during Sprints – is filled in by additional examples in the specification. For this reason, the specification is usually called Living documentation.
It also creates a common ground around which the multitude of stakeholders can discuss how the product or service should work.
Contrary to classical Waterfall models which have, by design, very cumbersome change request mechanisms, Specification by example will probably continue to evolve throughout the entire life of the project.
An example will help better explain this:
Story: Returns go to stock.
In order to maintain stock,
As a tool-store owner,
I want to add items back to stock when they are returned.
Scenario 1: Returned items should be returned to stock.
Given a customer previously bought a hammer,
And I currently have three hammers left in stock,
When he returns the hammer for a refund,
Then I should have four hammers in stock.
Scenario 2: Replaced items should be returned to stock.
Given that a customer buys a philips screwdriver,
And I have two philips screwdrivers in stock,
And three flat-head screwdrivers in stock,
When he returns the philips screwdriver for a replacement in flat-head,
Then I should have three philips screwdrivers in stock,
And two flat-head screwdrivers in stock.
The language that is used (Gherkin) is declarative, using the business terminology, intentionally avoiding any references to UI elements or any underlying technology.
An experienced tester should immediately call out edge cases: what happens when you exchange the philips for a flat-head and there are none in stock?
These edge cases should be addressed as soon as possible by the business analyst (by specifying additional examples), but even before then both development and testing can begin on the available scenarios.
Test automation is quite possible to derive from Specification by example documents.
In fact BDD – Behavior-Driven Development – is a process that depends on an ubiquitous language that is used to write tests. This language tries to mimic syntax of human language, so that non-technical people can easily understand it (and even write it), and is normally very domain specific.
There are test tools on the market (including HipTest from SmartBear) that specifically support BDD. It is not uncommon that a full DSL – Domain Specific Language – is developed first, incorporated into the application, and then is used to write all the automated tests, which in turn serve as the Specification by example.
Specification By Example is no catch-all solution.
Of course there are areas that will be missed by this. Specification By Example is no catch-all solution. It is rare that non-functional requirements will be discussed in Specification by example.
Additional mechanisms will need to be put into place: exploratory testing, usability testing, performance testing, security testing, and others all still need to be performed.
API and Service Virtualization
Obviously testing before you have any code to test presents an interesting conundrum.
In the simplest case, if you write a unit test before you write the function, in most languages will not even compile. This is solved by stubbing the method. A method stub is a piece of yet-to-be-written code.
It only satisfies the requirements that the code compile, so that we can prove the very first step of TDD: verify the test fails.
In situations where multiple systems communicate with each other, but not all the systems are available, you may need to resort to mocking or API virtualization. Mocking involves more than just a method stub, an actual piece of software, such as an API endpoint, that has some rudimentary functionality.
A simulation is similar to a mock, but the functionality provided is more complex.
 A simulation is similar to a mock, but the functionality provided is more complex.
A simulation is similar to a mock, but the functionality provided is more complex.
For example: let's say that your application needs to communicate with a payment system. A mock would reside at some endpoint and always reply in the positive, so that development and testing of other areas can resume.
A simulation could have a specific account that always replies in the negative (a closed account), and another account that only has $1 (to test overdrafts), to allow for more detailed testing scenarios.
Lastly virtualization is a fully deployable system.
Again using the example of a payment system, your payment broker could set up a fully functional test environment that you are able to connect to your system, or provide you with a system that you can deploy yourself into a virtual environment.
In this case the only thing that is different from production is the data – using real customer payment data for testing purposes would probably be a security risk (or possibly a violation of laws), but if the data is obfuscated in some fashion and deployed in a virtual environment everything should be satisfactory.
Virtualization is covered separately in the Best practices: API Mocking.